
The company operates in the omni-channel retail, leisure, wellness, food, and hotel sectors. It has a large presence in the Middle East, India, and South-East Asia with over 2,200 outlets in 24 countries.
THE CHALLENGE
The company had adopted an industry leading enterprise-wide data management and analytics platform. This scalable platform enabled their business users to develop solutions on assortment, pricing, demand forecasting and customer experience etc. With this, the company created thousands of customer microsegments, based on which they were able to customize their different market offerings and customer experiences.
In the existing IT environment, data was extracted from different source systems such as Oracle Cloud ERP, Epsilon solutions etc. The current solution included Jupyter notebooks with Python programming and other machine learning models. The output from these models was provided to management executives, business users, store managers etc through different front-end tools.
While this integrated platform provided the company’s users with various capabilities which helped them in strategic and operational decision making, the annual license costs were expensive. Additionally, the documentation for the existing platform was incomplete and not up to date. Some of the IT consultants who had developed the platform were no longer part of the organization. Due to this, the business users were not completely certain on the underlying rules and logic used in the platform for data transformation and processing. Also, not all the pipelines were configured to run automatically. Some high priority pipelines had to first be manually configured and then triggered, for the required output.
To address all these issues, the company needed a partner to help their in-house IT division migrate from the existing data management and analytics platform to a new Databricks platform on the Microsoft Azure cloud.
THE SOLUTION
The team of data engineers and data scientists from Prescience Decision Solutions was a key part of the migration to the Databricks platform for the company’s Merchandizing and Customer divisions. The company expected the new solution to function in the exact same way as the existing data management and analytics system.
During their initial analysis, our team identified multiple technical and process issues such as missing source tables, lack of documentation for many components, necessity for updates in the underlying business logic and calculations and made several recommendations for improvements.
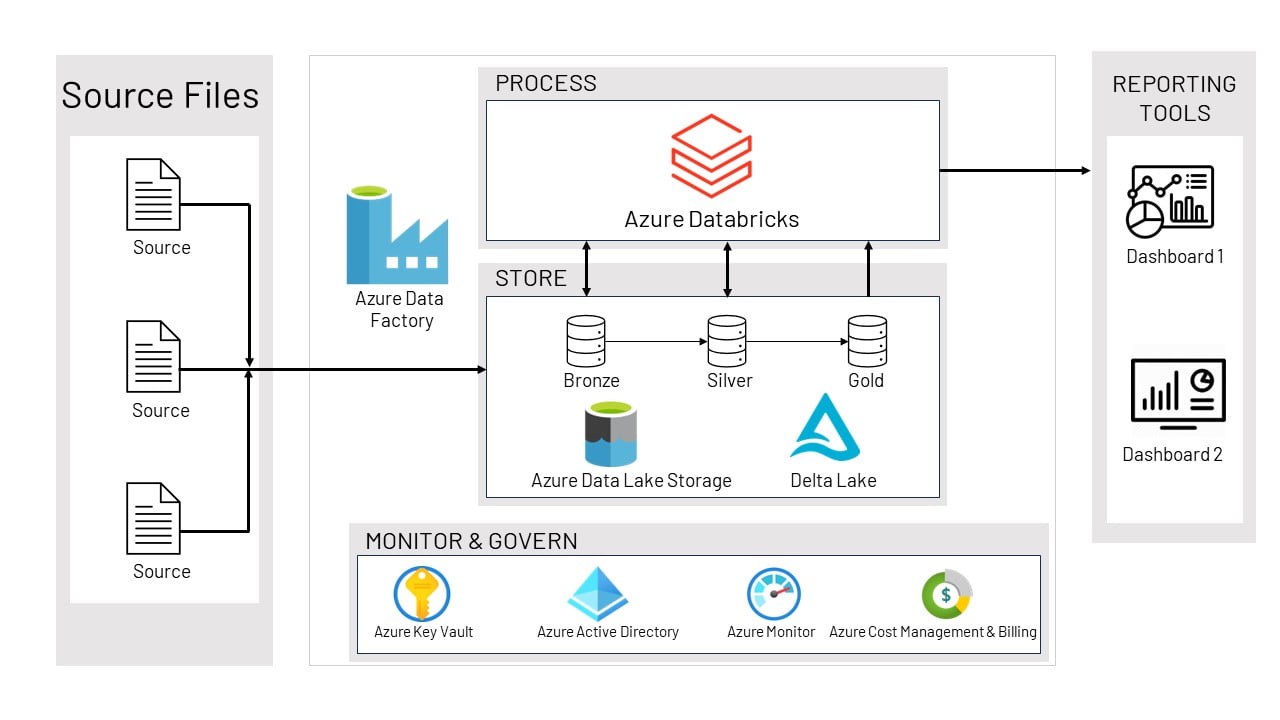
The new solution included the implementation of the Azure Data Lake for distributed data processing. PySpark notebooks was used on the Databricks solution. The Databricks platform uses a Medallion architecture which includes the following 3 data layers,
- Bronze Layer
- Silver Layer
- Gold Layer
The raw data is extracted from the source systems and stored in the Bronze Layer. This data from the Bronze Layer is extracted for pre-processing and then stored in the Silver Layer. The cleansed and standardized data in the Silver Layer is used by the different machine learning models. The output of these is stored in the final Gold Layer. This data is then made available to the several decision makers, business users, store managers etc through the existing front-end tools. With this Databricks platform, the data management can be executed in parallel, thereby directly leading to substantially reduced data processing and execution times.
Our team made several improvements to the data management process including reducing the overall number of tables required. They also performed data reconciliation and testing for all the migrated components on the Databricks platform.
THE IMPACT
With the help of the team from Prescience Decision Solutions, the company was able to reduce the timeline for the overall migration from the legacy platform to the Databricks on Azure platform. Our consultants identified numerous business and technical gaps in the existing solution, prior to the component migration. The execution times for the migrated components on the Databricks solution were far less than that of the existing platform. This directly resulted in the company’s business users being able to access their critical data much faster than before, thereby improving their operational efficiency.
The team also optimized and recreated some of legacy pipelines by using various design patterns like factory, abstract factory to make it more modular, reusable, and scalable across products and categories. With this approach, the team was able to reduce ~ 3 – 4 % duplicate and unnecessary Spark code from the legacy system.


